Create an Anonymization Generator
To create a generator, you first need to select a source to be used as its basis. This process can be initiated from the generator creation dialog, where you can also optionally specify a name. You will also need to select the type of generator you want to create, which in this case is ‘Anonymization’.
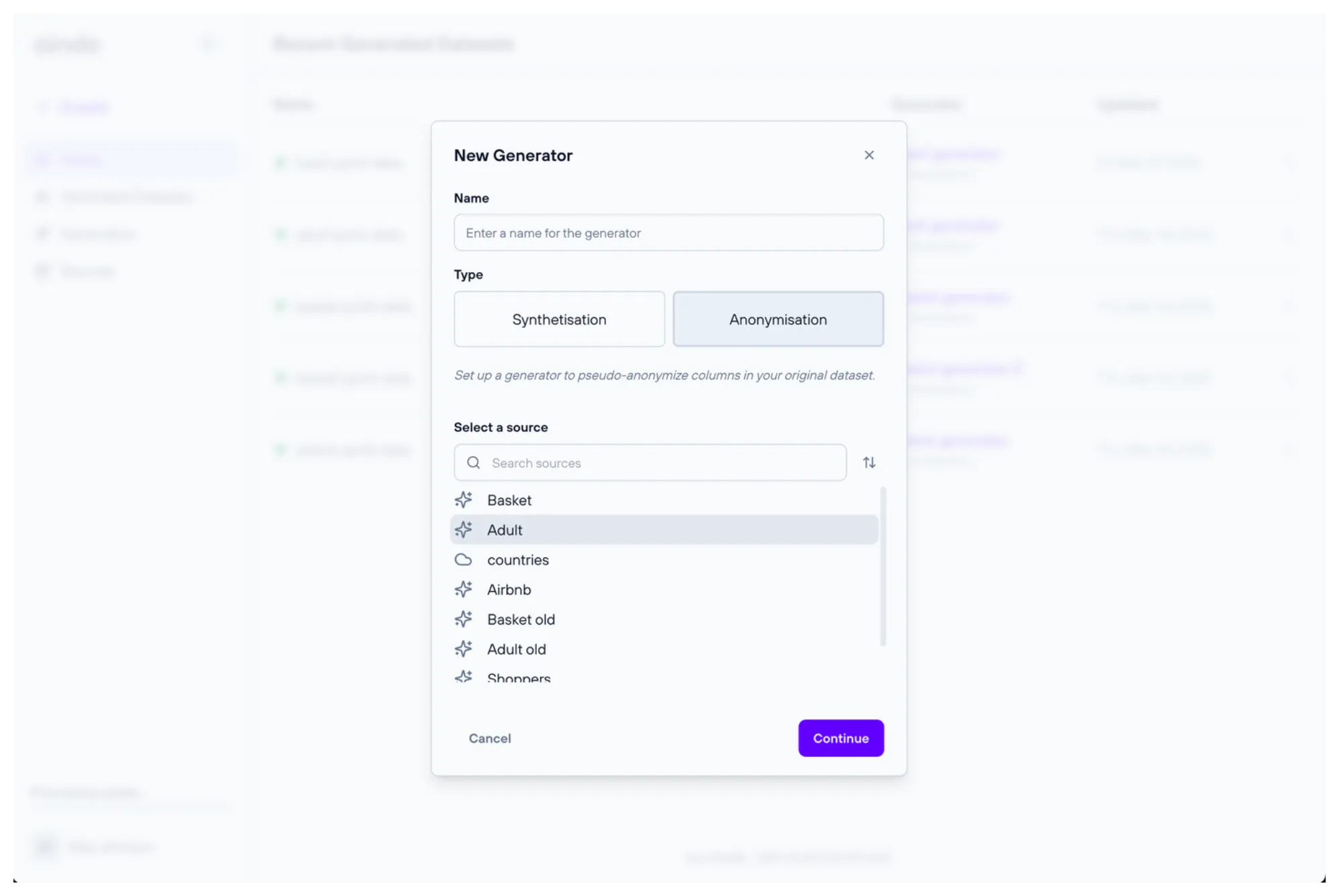
Configuration steps
Before creating the generator, the configurator allows you to review and modify some properties of data that will be used.
1. Choose data
The ‘Choose data’ step allows you to include or exclude specific tables and/or columns from the selected source.
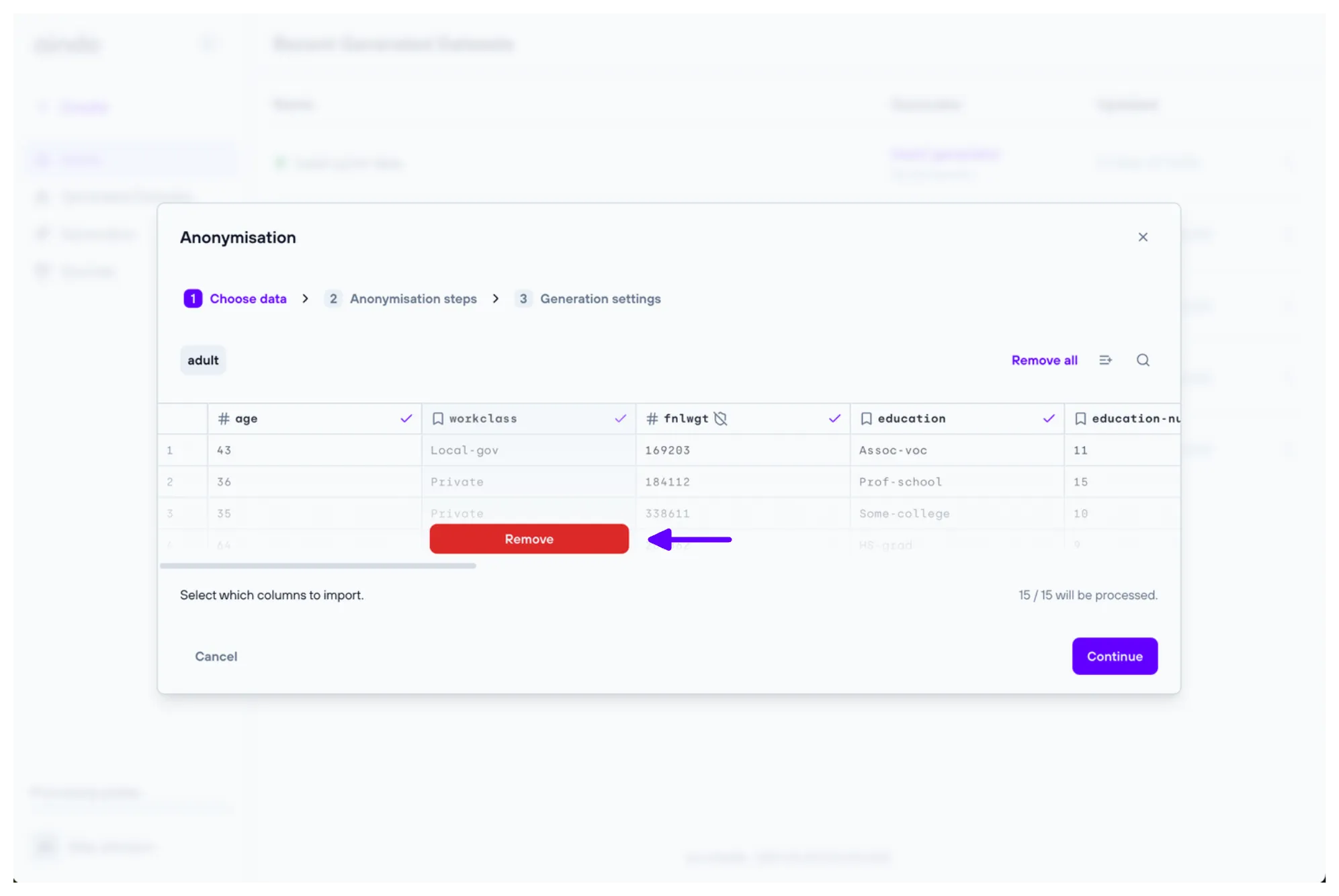
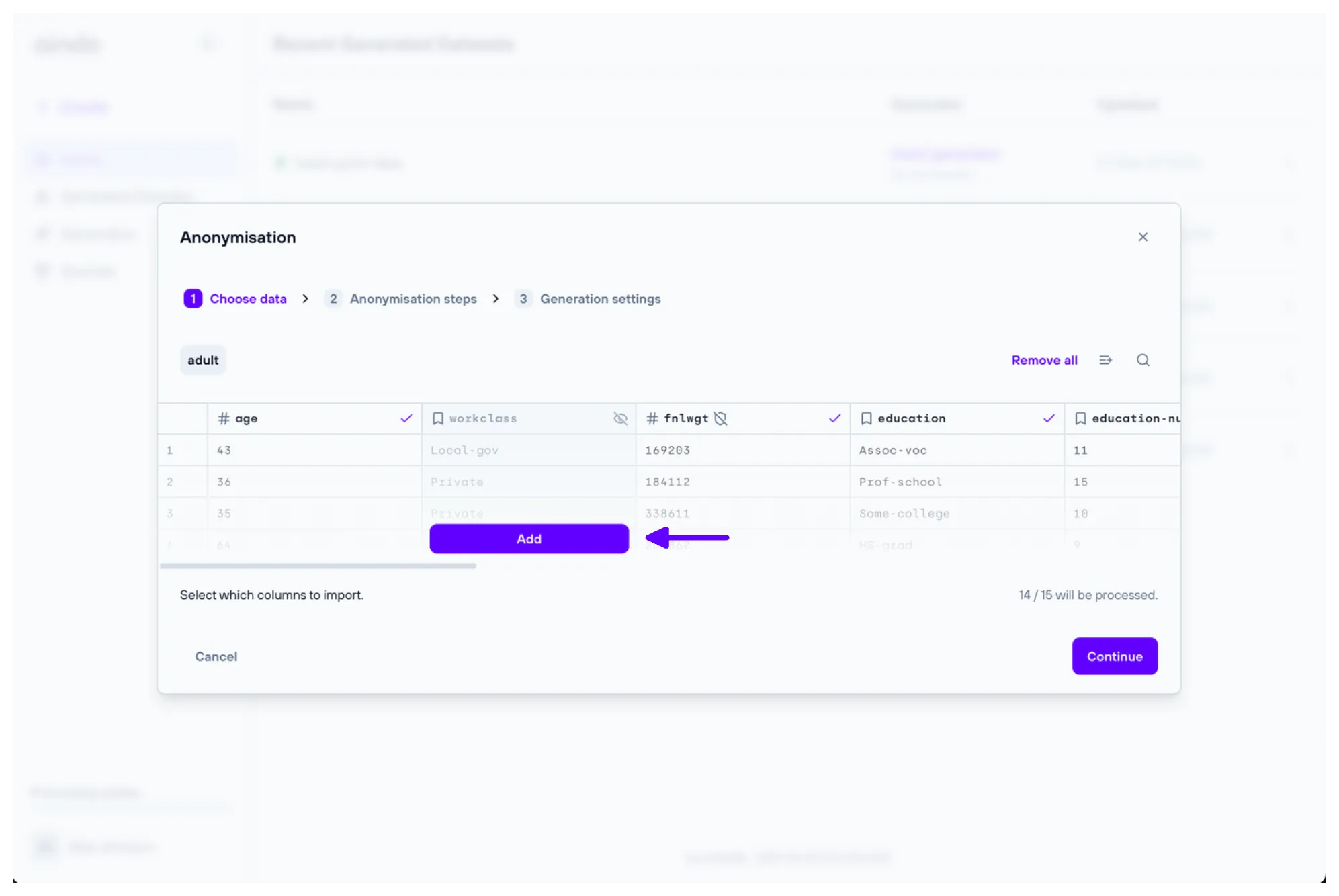
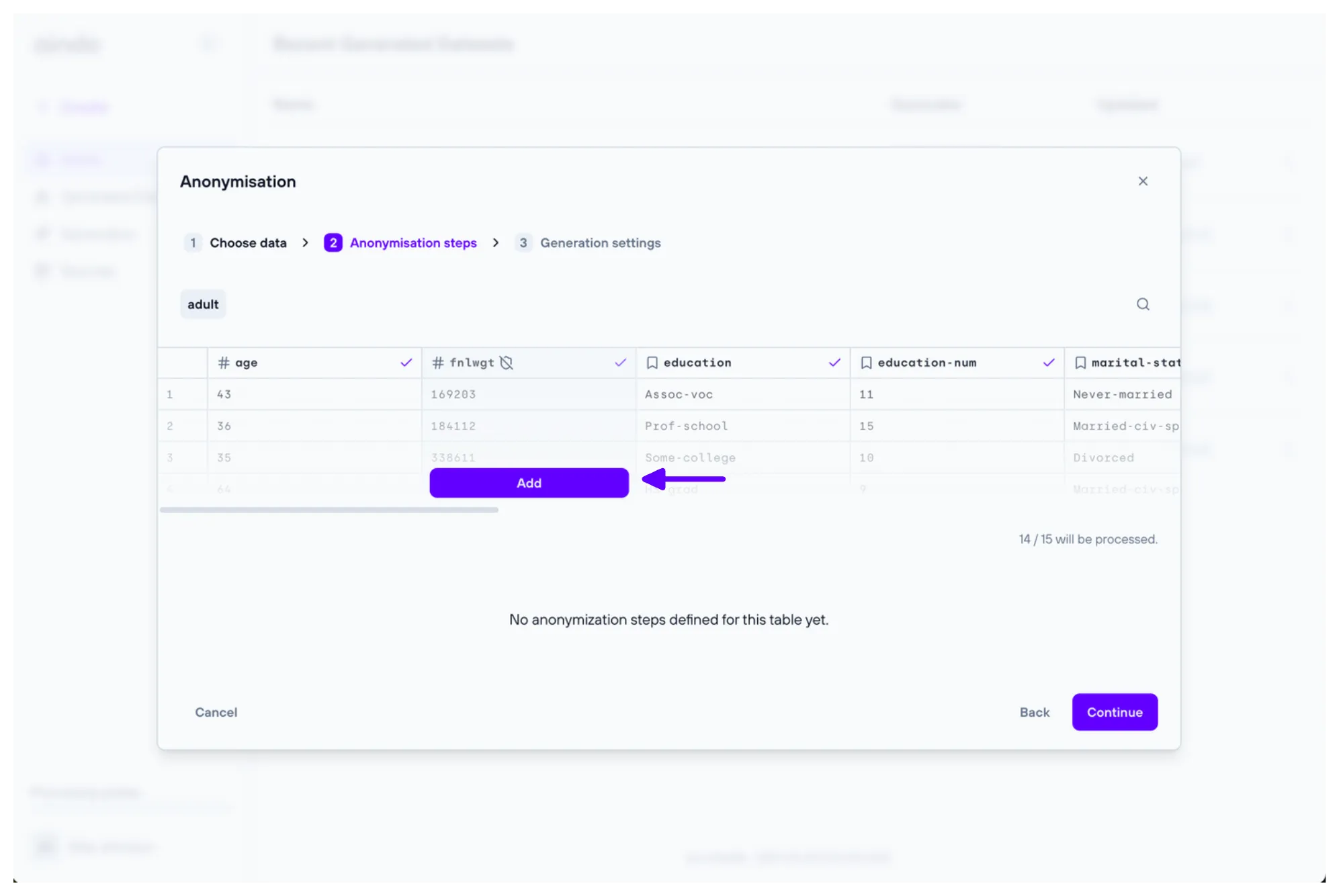
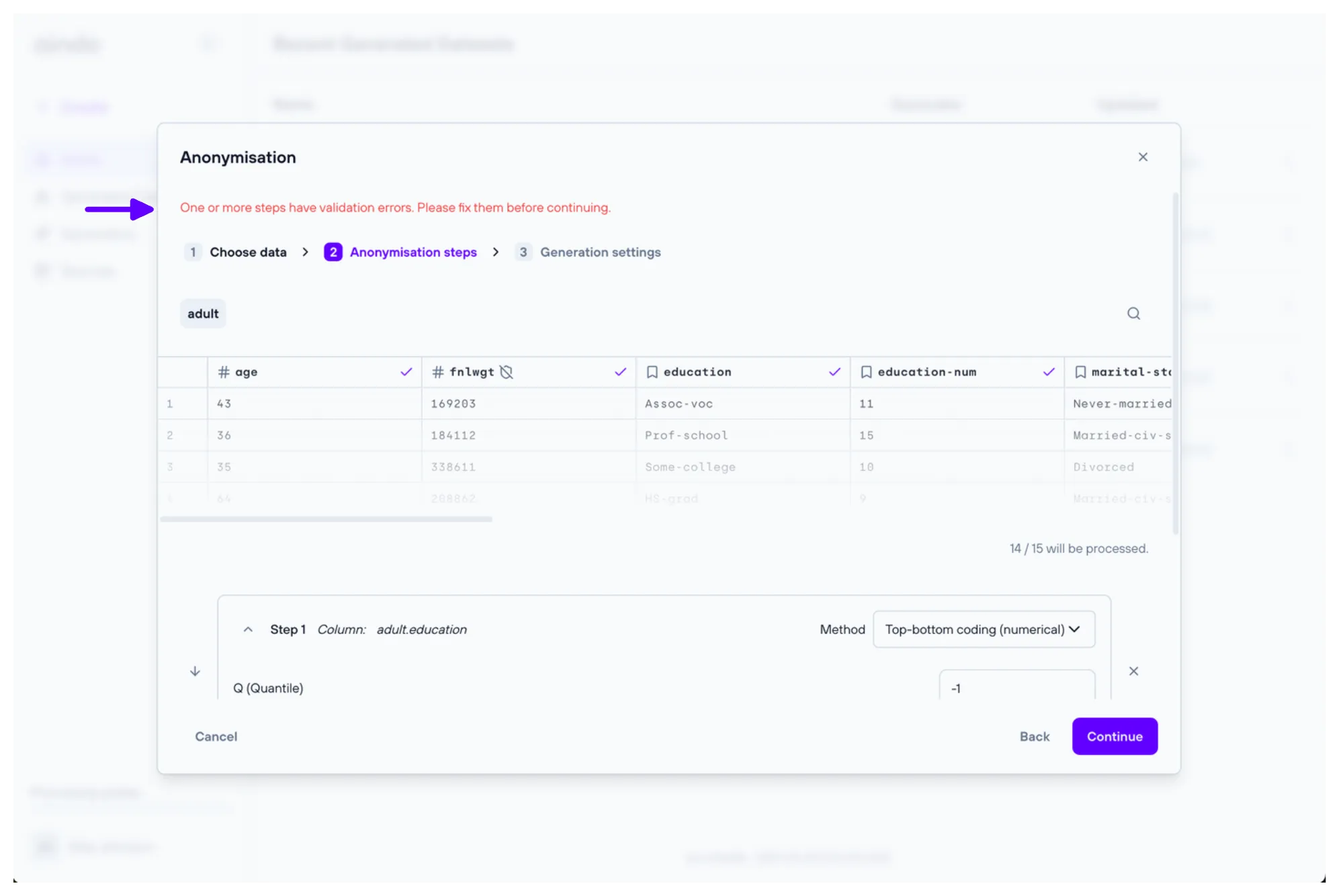
2. Anonymisation steps
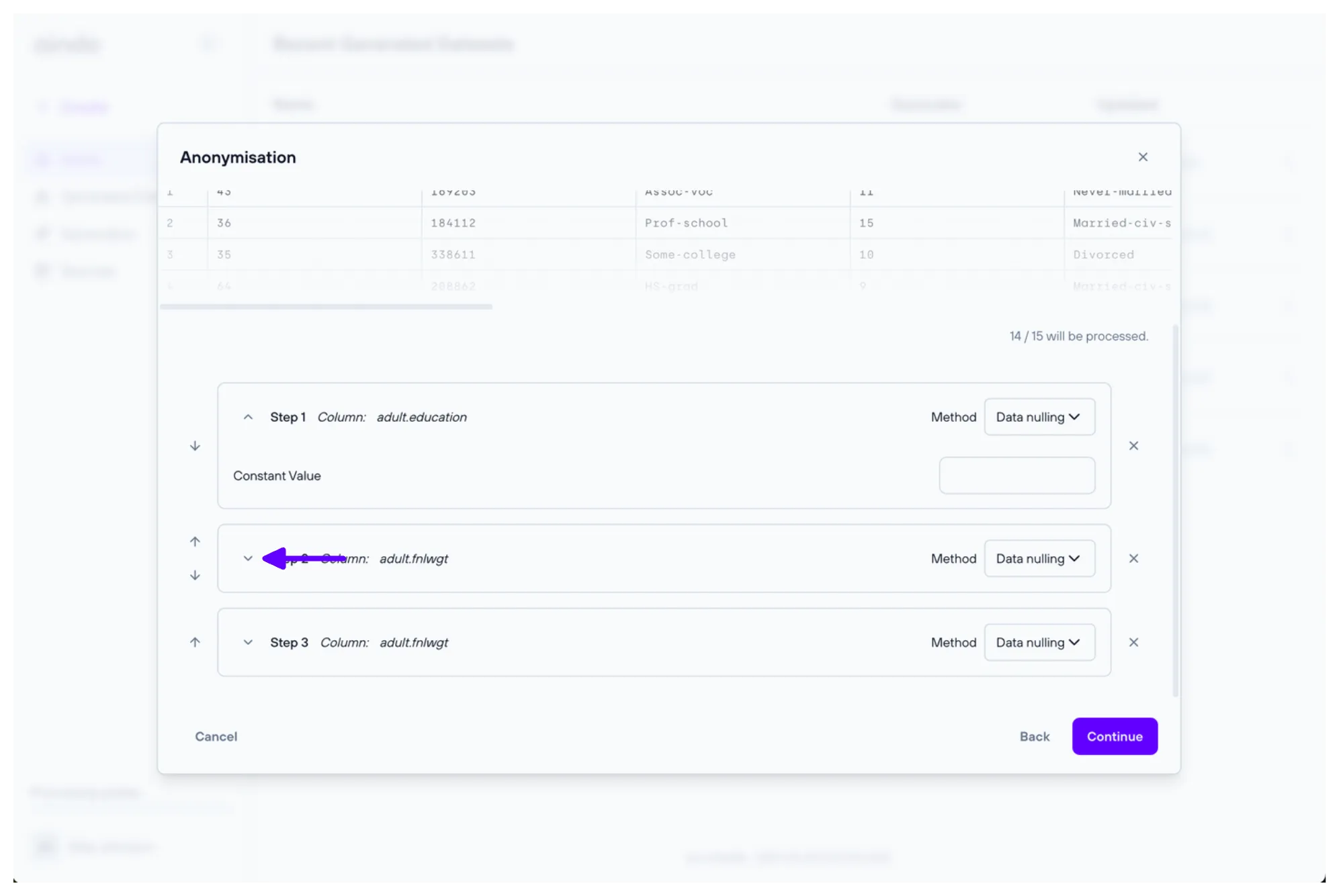
The ‘Anonymisation steps’ step allows you to add anonymisation steps to the generator. Each step will apply a specific anonymisation technique to a given column. Multiple steps can be added to the same column, and they will be applied in the order they are defined.
Available techniques include:
- Data nulling: Replaces the original data with None or a custom constant value.
- Character masking: Replaces some or all characters with a constant symbol.
- Mocking: Generates realistic mock data for various fields, such as names, emails, and more.
- KeyHashing: Data values are hashed using a cryptographic key and then encoded using Base64.
- Swapping: Rearranges data by swapping values.
- Binning: Groups numerical values into discrete bins and replaces individual values with their corresponding bin ranges.
- Top/Bottom coding: Replaces values above or below certain thresholds with a capped value.
- Perturbation: Slightly modifies the values according to the specified perturbation intensity and replacement strategy.
For more details about each technique, see Anonymization Techniques.
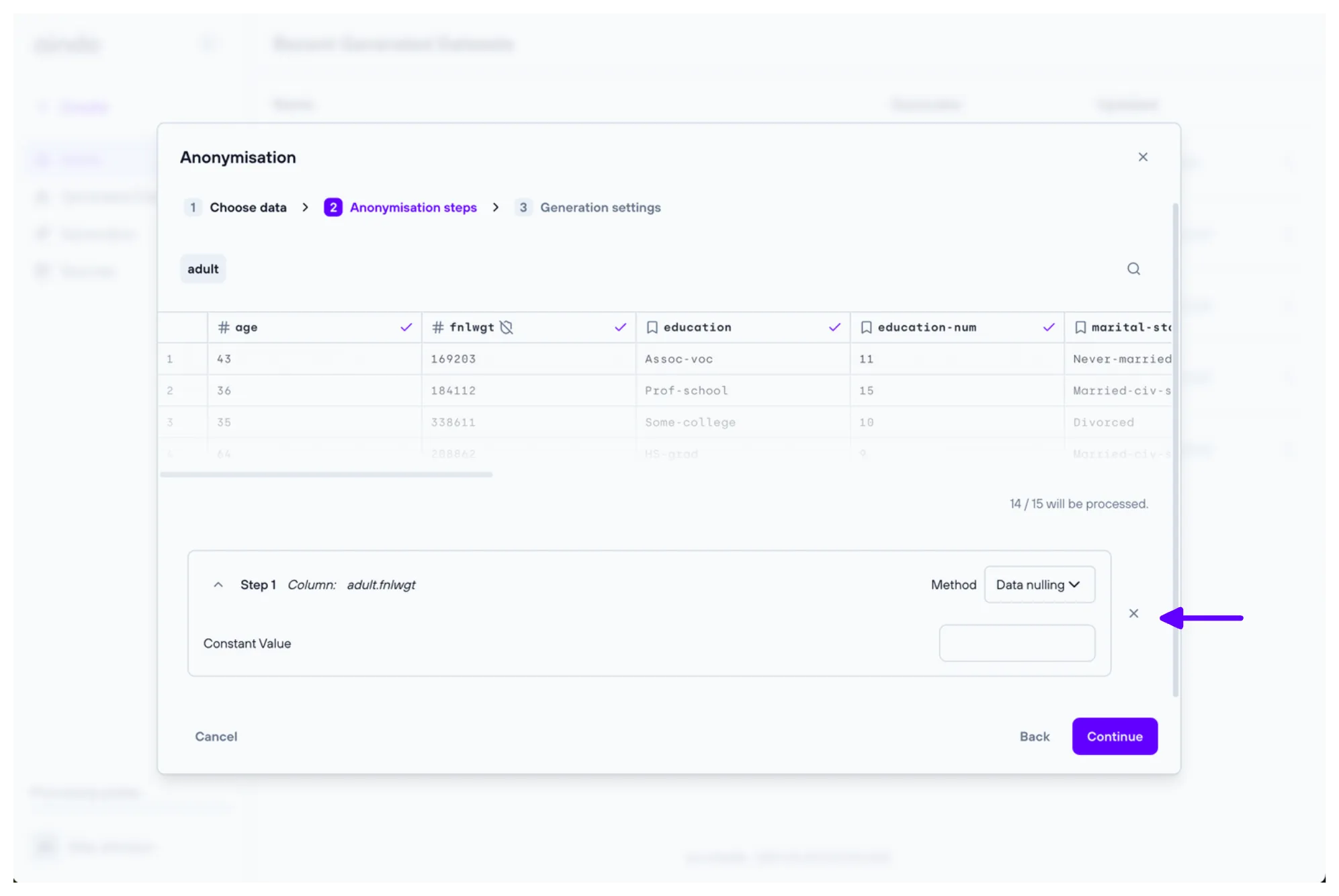
Steps beyond the latest one are collapsed by default. You can toggle the step details by clicking on the step expansion icon.
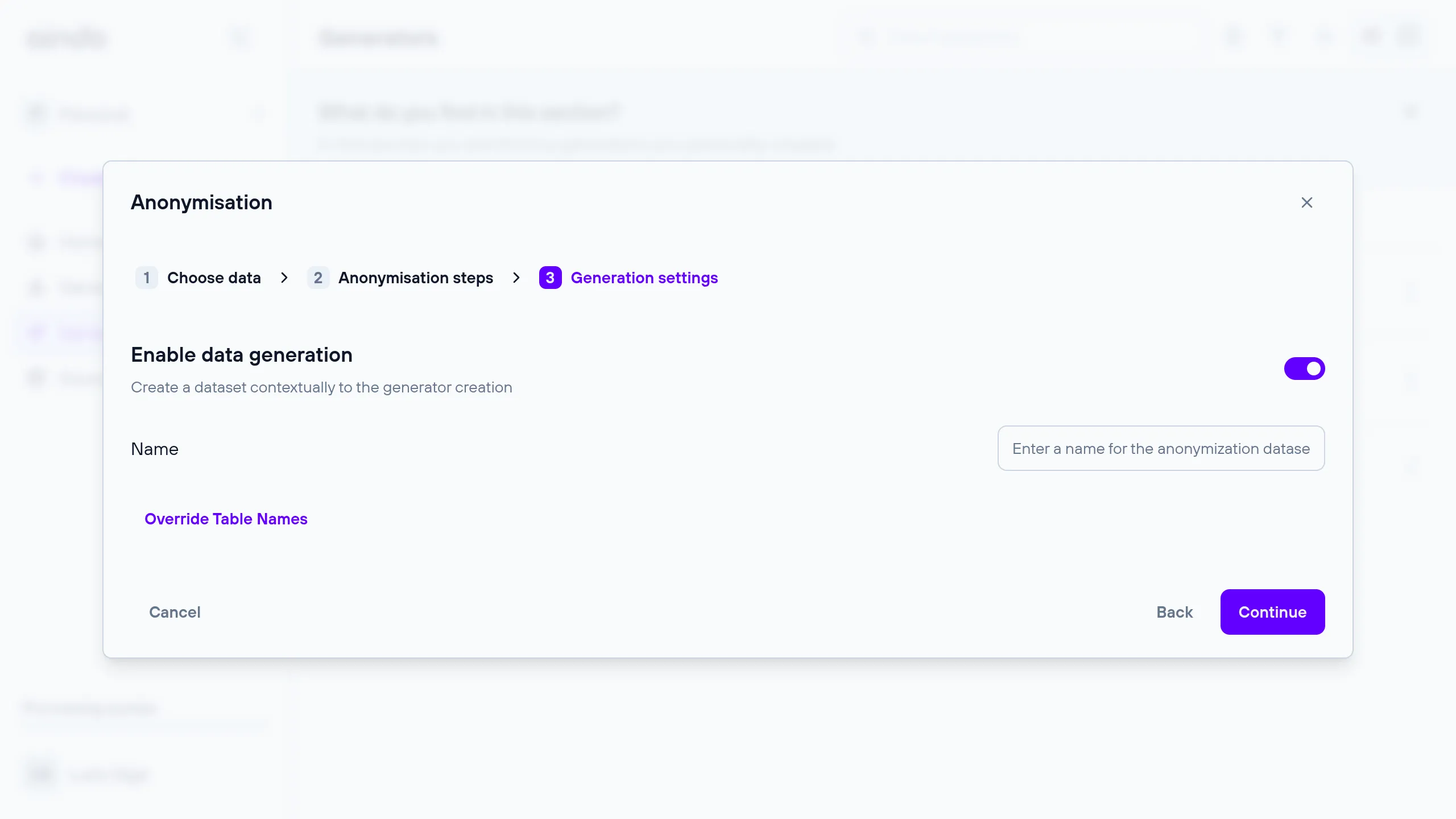
3. Generation settings
The ‘Generation settings’ step allows you to enable or disable the data generation once the generator is ready. By default, it is enabled.
Here you can also specify a name for the generated dataset.
Override Table Names
If you need more control over the names of the generated tables on the destination, you can open the “Override Table Names” menu. Here you will be able to specify a different name for each table.
Configuration validations
Each configuration step may have constraints that need to be satisfied to create a fully functional anonymization. The configuration process guides you through meeting these constraints by displaying alerts when they are not satisfied.
Choose a destination
After selecting the configuration, you will be prompted with a dialog where they can choose a destination for writing the anonymized data.
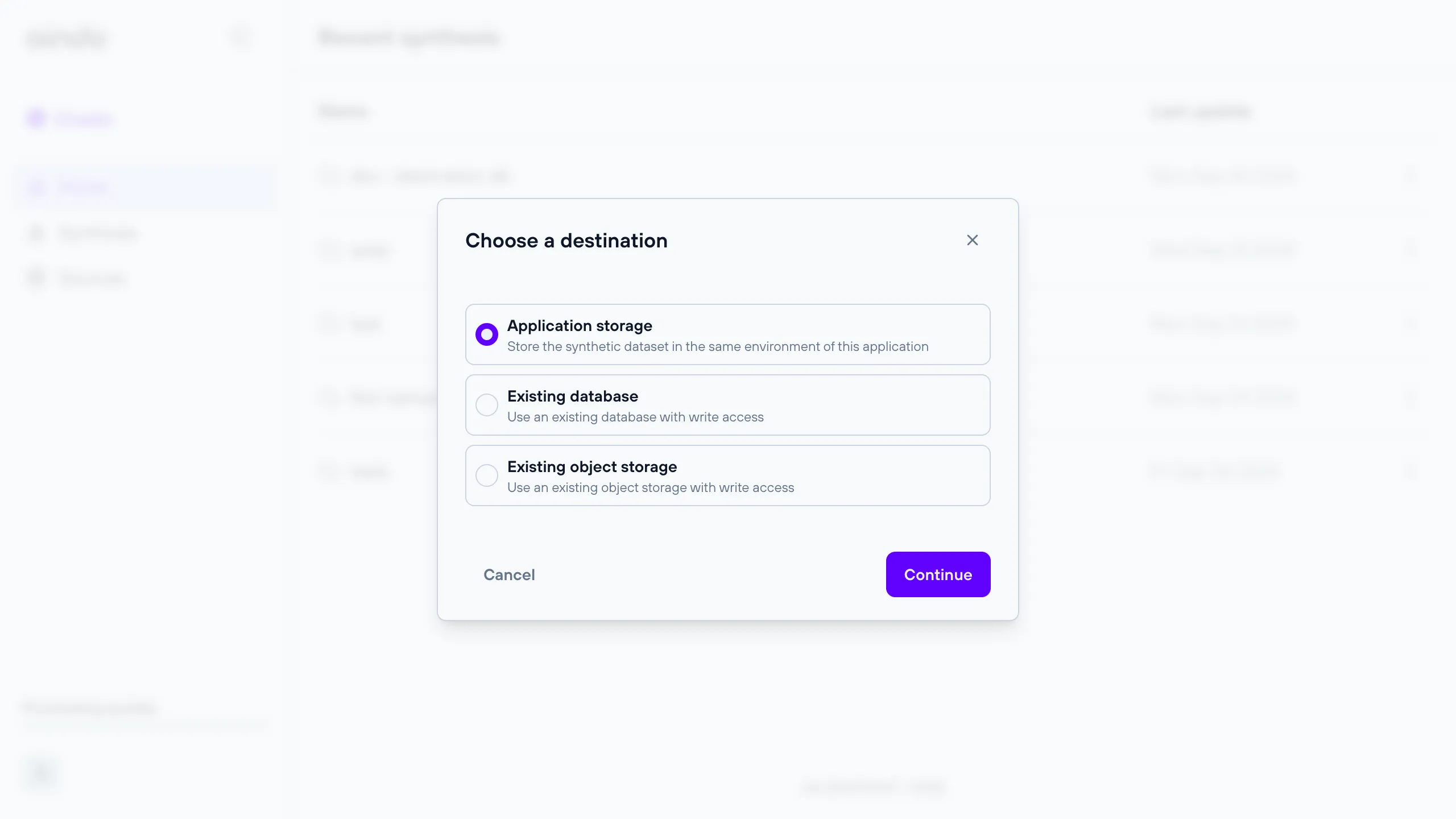
See the sections below for more details about each choice.
Application storage
A storage managed by the application, either on the cloud or locally for on-premises deployments. This is the default destination.
Remote database destination
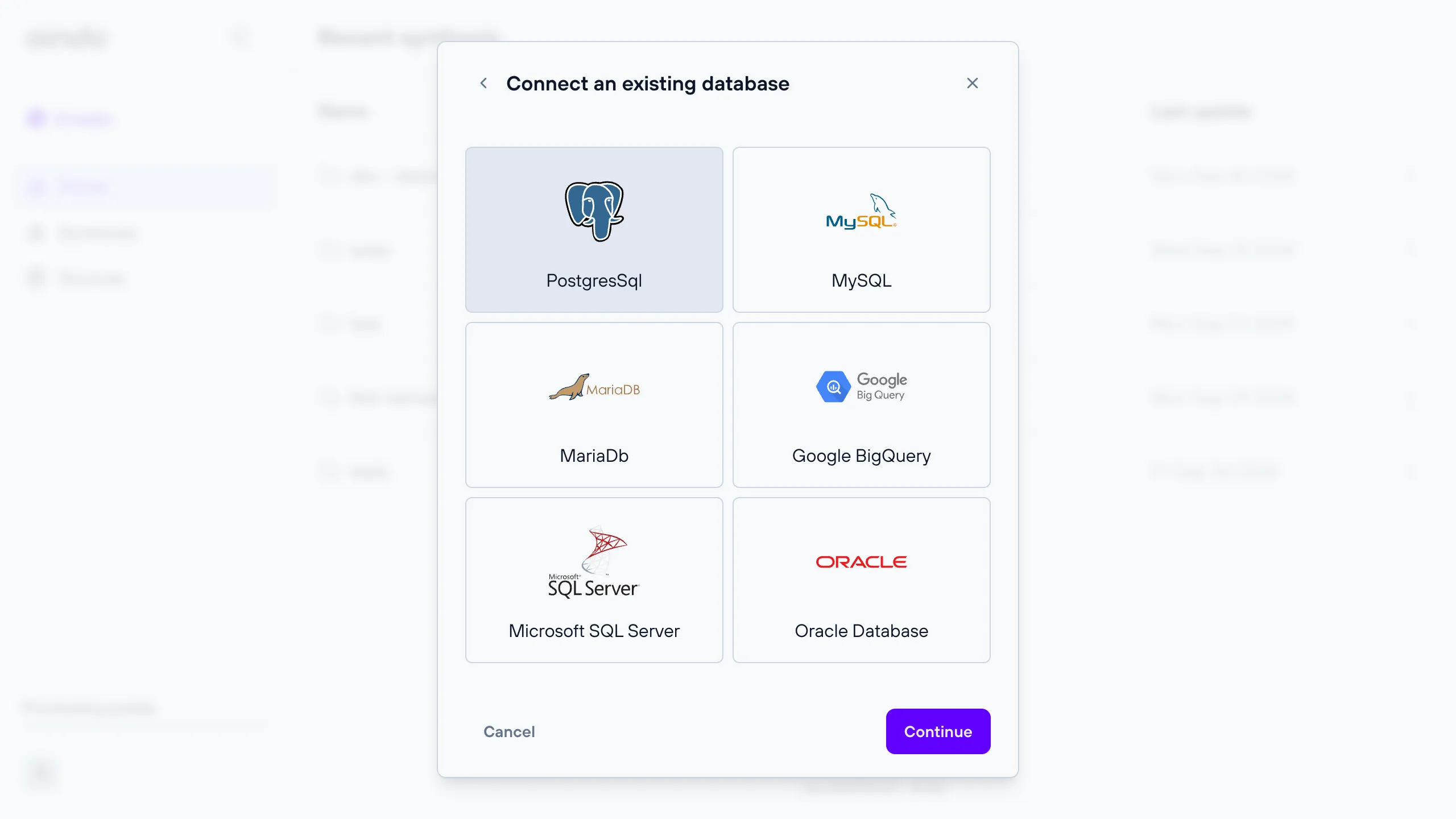
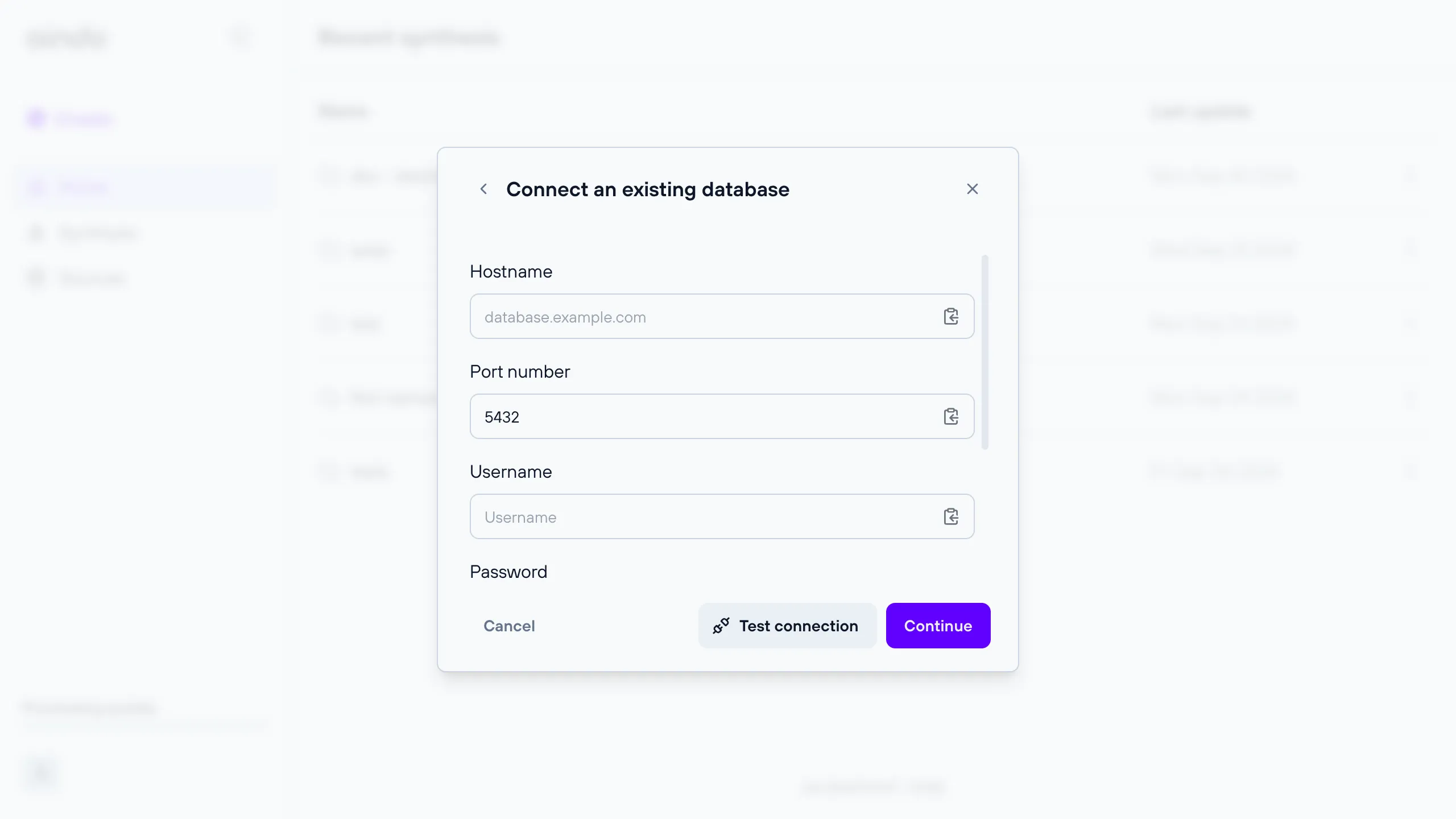
A remote relational database for which you can provide connection details.
All databases that are available when configuring a data source are also available as destinations. This includes PostgreSQL, MySQL, MariaDB, Google BigQuery, Microsoft SQL Server, and Oracle Database.
Note: The provided connection details must allow write access, otherwise the anonymized dataset cannot be saved.
Remote object storage destination
A remote object storage for which you can provide connection details.
Note: The provided connection details must allow write access, otherwise the anonymized dataset cannot be saved.
All object storages that are available when configuring a data source are also available as destinations. This includes S3 and Google Cloud Storage.
When using an object storage as destination, object keys will correspond to the names of contained tables: these do not
include file extensions such as .csv unless they are also present in the table name.
Troubleshooting
If you encounter any issues, here are some common problems and their solutions:
- Create button returns configuration error: If there are no validation errors during configuration but the anonymization creation still fails, there may be other unsatisfied constraints. Carefully read the error message for hints about the failed configuration, or contact support for assistance.
- Preview of data in configurator fails: The source data used to configure the anonymization may no longer be available or may have changed connection settings.
- dataset too small: If a dataset has too few records, anonymization may not be possible.
- quota limit reached: See quota errors
FAQ
Q: What should I do if the “Create” button returns a configuration error?
A: If there are no visible validation errors but the anonymization creation still fails, check the error message for hints about the failed configuration. Ensure all constraints are satisfied. If the problem persists, contact Aindo support for assistance.
Q: Why does the preview of data in the configurator fail?
A: This issue may occur if the source data is no longer available or if its connection settings have changed. Verify that the source data is accessible and that connection settings are correct.
Q: What can I do if my dataset is too small to generate anonymized data?
A: If the dataset has too few data points, anonymization may not be possible. Consider gathering more data to increase the dataset size.
Q: What are quotas and how do they affect anonymization runs?
A: Quotas are resource limits defined on the platform. Each anonymization run consumes resources, which count against your quotas. If you run out of quota, you won’t be able to create generators. Check your quota status and manage your usage accordingly.
Q: How do I know which columns need to be anonymized?
A: Columns marked with a gray ‘shield’ icon in the ‘Data treatment’ step indicate that they contain sensitive data. These columns should be anonymized to protect the sensitive information.