Disaster Recovery
Before designing a Disaster Recovery (DR) strategy, it is essential to define your specific use case, risk tolerance, and the types of disasters you aim to protect against (e.g., region-wide outages, accidental deletions, security breaches).
The design and implementation of the DR solution depend heavily on whether the deployment is cloud-based or on-premises, as the two environments differ significantly in architecture, available tools, operational responsibilities, and recovery capabilities.
In cloud environments, the initial focus should be on building highly available infrastructure within a single region, leveraging multi-AZ (Availability Zone) architectures, redundant storage, and distributed services, as this often mitigates many common failure scenarios. Only after establishing such a resilient foundation should DR planning extend to cross-region failover or full cluster recovery strategies to address broader catastrophic events.
Conversely, for on-premises Kubernetes, DR planning must include physical redundancy, offsite backups, and detailed procedures for rebuilding or failing over to an alternative data center, as the underlying infrastructure reliability falls entirely within the user’s responsibility.
Because DR depends on many factors, this guide does not attempt to cover every possible scenario. Instead, it presents a reference cloud deployment that combines high availability across multiple Availability Zones with a disaster recovery strategy that includes replicating backups to a secondary region. The diagram below illustrates this deployment: Worker nodes are distributed across multiple Availability Zones to increase resiliency in case of a localized outage. The control plane is managed by the cloud provider and is typically configured for high availability by default.
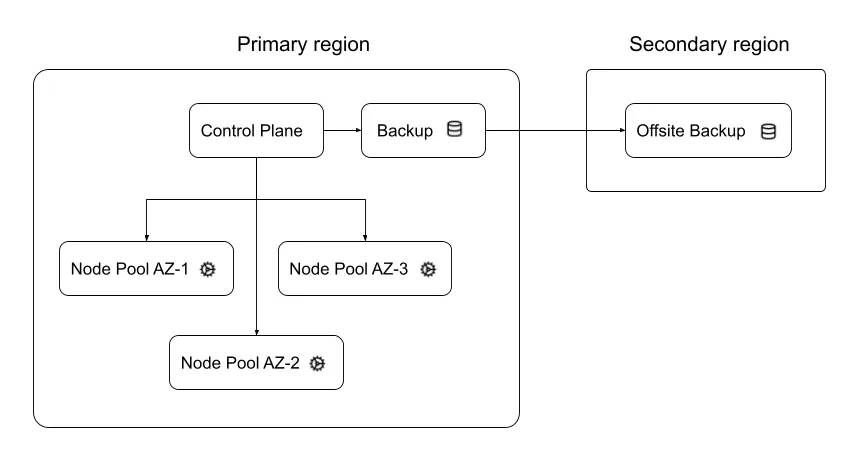
To take full advantage of multiple Availability Zones, configure your workloads with (1) a sufficient number of pod replicas (at least equal to the number of AZs, three in this example), and (2) topology spread constraints to ensure that pods are evenly distributed across cluster nodes. Each component of the Aindo Synthetic Data Platform can be scaled independently, and custom scheduling constraints can be applied as needed using the Helm chart provided by Aindo for installation.
The Aindo Synthetic Data Platform needs a database, a Redis cache, and an S3-compatible object storage to work correctly (see the Architecture documentation). These services can either be externally managed or deployed within the Kubernetes cluster. In this example, all services are deployed inside the cluster, so only the Kubernetes cluster needs to be backed up.
The cluster is configured to use the cloud provider’s native backup service to protect both resources and persistent volumes. Backup data is stored in an object storage bucket, with a copy replicated to a secondary bucket in a different region. This setup ensures data recovery and cluster re-creation capabilities in case of a regional failure.
The effectiveness of a backup plan depends on regular testing of the restore process. To ensure reliability, perform a DR simulation at least once per year by rebuilding the infrastructure from scratch. This helps identify any weaknesses in the DR strategy before a real incident occurs.