Data preparation
High-quality, well-formatted real data is crucial for generating valuable synthetic data. The structure of the real data plays a significant role in determining the complexity of learning its underlying statistical distribution. Fortunately, simple data preparation procedures can substantially enhance the quality of both the source data and the resulting synthetic data. In this section, we will outline best practices for data preparation to optimize the synthesis process.
Constraints
Data structure
Before starting the synthesis process, ensure that your data adheres to the following structural constraints:
Definitions
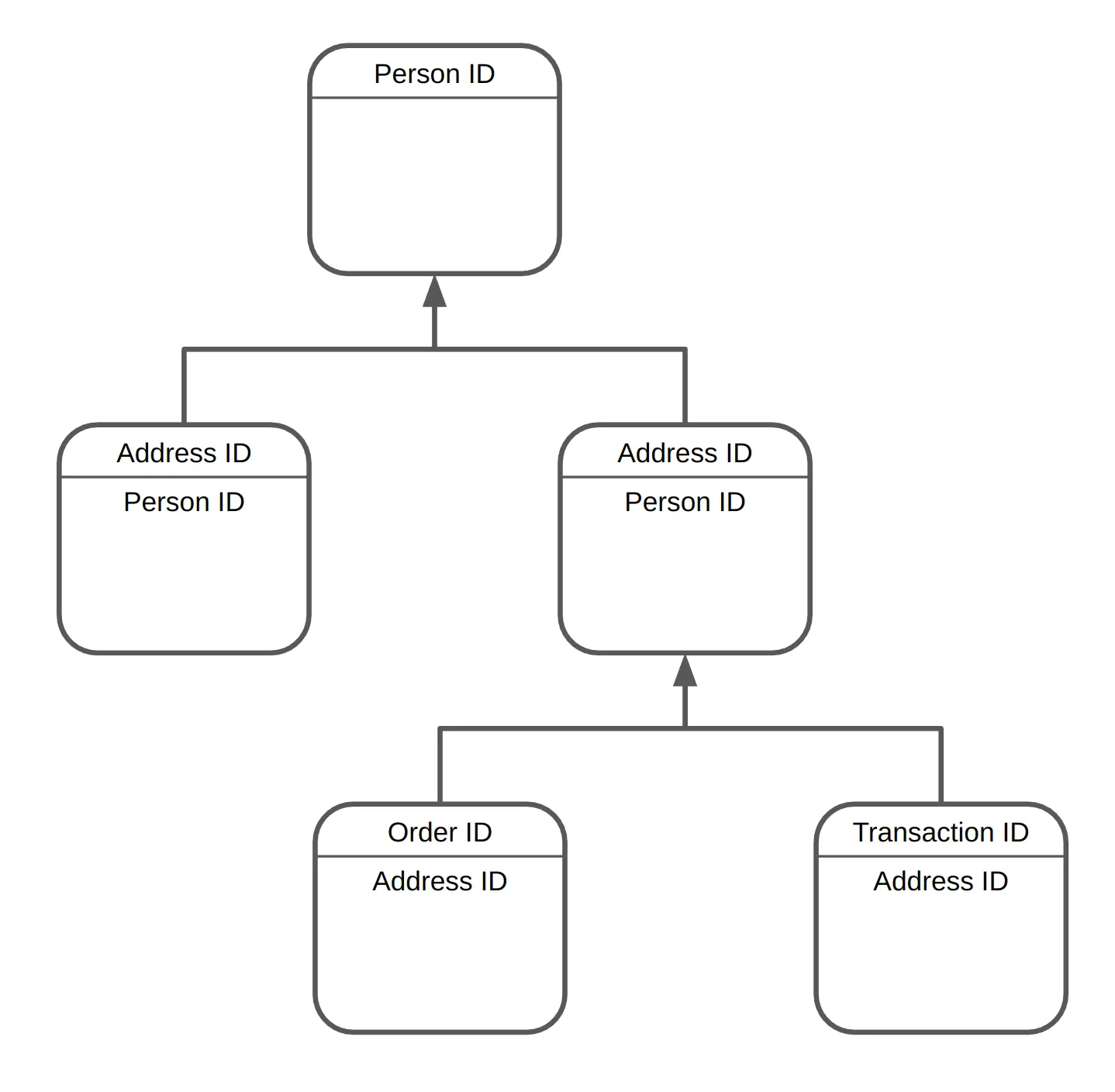
- Root Table: In the relational data model, there must be a single root table that serves as the primary entry point. This table should not contain foreign keys referencing other synthesized tables but may reference lookup tables (see definition below). Each row in the root table represents an independent and identically distributed (IID) sample.
- Lookup Table: A lookup table contains reference data that will not be synthesized. The model will only synthesize relationships between other tables and the lookup table.
Constraints
- Each non-root table must contain exactly one foreign key that references the primary key of a table that is not a lookup table.
- Composite primary keys are not supported.
- Null values in foreign key columns are not allowed.
- Foreign key loops are prohibited: no foreign key in the structure should create a cycle.
- The relational structure of the synthesized tables must form a rooted tree, where one table has no foreign key (the root), and all tables are connected by a unique path (see image below).
Subjects and components
The first step in effective data synthesis is understanding the concept of independent and identically distributed (IID) components. Aindo’s models infer distributions based on these IID components. In relational data, rows may not always be IID.
For example, consider a database with two tables: one for client data and one for purchase records. Since one client can have multiple purchases, the rows in the purchases table are not IID. In such cases, Aindo’s synthetic data generator identifies IID components—rather than looking at individual records, the generator processes larger components that satisfy the IID condition.
Independent Identically Distributed Components
- Components: A component is a set of rows within the relational dataset that refer to the same entity or subject, connected through foreign keys either directly or indirectly. A component includes all rows reachable from a single row by recursively traversing foreign keys in any direction.
- Independent: Each component is independent of others. There is no relation between the attributes of different components.
- Identically Distributed: All components come from the same underlying probability distribution.
A component represents a single entity or subject and should contain all relevant information about that entity or subject in the data.
In the case of a single root table (the scenario currently supported by Aindo), each component consists of one row from the root table along with all associated rows from other tables that are linked via foreign keys. Each row in the root table uniquely identifies a component.
Let’s use a practical example to illustrate these concepts. Consider a relational dataset with three tables: “Accounts”, “Transactions” and “Investments.”
- Accounts Table (Root): This table contains information about individual customer accounts (e.g., account ID, holder’s name, and account type). Each row is uniquely identified by the account ID.
- Transactions Table: This table records financial transactions (e.g., transaction ID, date, amount, and associated account ID). The account ID in the “Transactions” table links each transaction to the corresponding account in the “Accounts” table.
- Investments Table: This table stores data related to customer investments (e.g., investment ID, type, quantity, and associated account ID). The account ID links each investment to the corresponding account in the “Accounts” table.
In this example, each component consists of one row from the “Accounts” table and all related rows from the “Transactions” and “Investments” tables, connected by foreign keys. Components are independent if none of the attributes within one component depend on attributes in another component. For instance, if a customer has multiple accounts, the components are not independent because transactions and investments from one account may affect others. Components are identically distributed if they originate from the same statistical distribution, meaning they are equivalent a-priori.
Best practices: obtaining IID components
Synthetic data generated with Aindo’s platform will consist of IID components. Since the components are determined by the relational structure of the data, modifying this structure can help ensure components are IID.
Here are some best practices to make sure your real data is IID:
- Ensure data integrity: Confirm that all rows representing a single entity or subject are reachable from one another through foreign keys, making sure they belong to the same component. If this is not the case, consider adding a foreign key to link two components that represent the same entity.
- Be cautious with temporal and sequential data: Ensure that such columns are adequately represented in each component. For instance, in a time series of transactions, each transaction likely depends on its preceding ones. Ensure that rows within the same time series are reachable from each other by traversing foreign keys.
- Maintain row order for time series: For time series or other ordered data, ensure that the tables are ordered according to their natural temporal sequence. This will make it easier for the model to learn the correct statistical pattern.
- Add extra columns to capture trends: When components are not identically distributed, consider adding attributes or tables to capture these differences. For example, if we are modeling the customer base of a service and the type of customers varies with time, the addition of the subscription date feature will help the model to correctly model this trend.
- Separate entities from events: When data includes both “static” information about entities (e.g., customers or patients) and “dynamic” event data (e.g., purchases or medical visits), separate these into different tables. Static data should reside in the root table, while event data should be placed in child tables. For example, in a healthcare dataset, patient information should be contained in the root table, while medical visits should be in a child table.
Data requirements
Number of subjects
To ensure effective model training, a large number of independent samples (see Subjects and components) is required to capture patterns and generalize successfully. Insufficient data can lead to poor model performance, with synthetic distributions failing to mirror the original data. It is difficult to predict the exact number of rows required for proper synthetic data generation because the complexity of the data’s probability distribution determines the number of samples needed. However, as a general guideline, we recommend that the root table contain at least 4,000 independent rows.
Number of features
Each component (see Subjects and components) will have a number of features equal to the sum of all columns of the rows that make up that component. During training and synthesis, components with a larger number of features demand more memory and computing power. Excessive features may exceed system limits and slow processing. For our reference architecture (AWS EC2 c6i.4xlarge instance), the maximum number of features across all components should not exceed 1,000 to optimize memory usage and computation time.
Information redundancy
Information redundancy can degrade the quality of the synthetic data by forcing the model to learn unnecessary information. To improve the generation process, ensure that the data contains only essential information needed to replicate its statistical properties.
Best practices
Here are some best practices to minimize information redundancy:
- Remove duplicate columns
- Define lookup tables: If certain columns contain attributes that always appear in fixed combinations, store these combinations in a lookup table. For example, if you have a “country” column and a “country code” column, create a lookup table to store these pairs.
- Eliminate columns that are derived from others: Columns that are functions of other columns (e.g., “total spending” and “average monthly spending”) should be omitted from the synthesis process. Instead, create the derived values from the synthetic data after synthesis.
Only include the necessary information for training the Aindo model. Derived data can be reconstructed from the synthetic data later using the primary columns.
Redundancy can also exist across rows within the same component. In these cases, it is better to consolidate strongly correlated columns into the same table and identify columns related by functional relationships or fixed combinations.
Data cleaning and formatting
Standard data cleaning improves both synthesis quality and training speed. Consider these best practices for cleaning and formatting your data to maximize the potential of the Aindo platform:
- Fix typos: Typographical errors can negatively affect both synthesis and training performance. For example, typos in categorical labels may cause the model to treat them as separate categories.
- Limit numerical precision: Excessive precision in numerical variables can unnecessarily increase training time. Use the appropriate level of precision for your data and ensure that data manipulations don’t artificially inflate decimal places.
- Ensure correct coordinate format: Coordinates should follow the ‘latitude, longitude’ format without the degree symbol. Latitude must range from -90 to 90, and longitude from -180 to 180.
- Use standard date and time formats: Ensure dates and times are formatted correctly, either as strings or Unix timestamps. Standard datetime formats are recommended for database connections.