View details and evaluate synthesis
The Aindo platform allows you to visualize both real and synthetic data, as well as details about the synthetization process. The platform also provides evaluation metrics to assess the quality and degree of privacy protection of the generated synthetic datasets. Below is an overview of the viewing, visualizing, and evaluation functionalities.
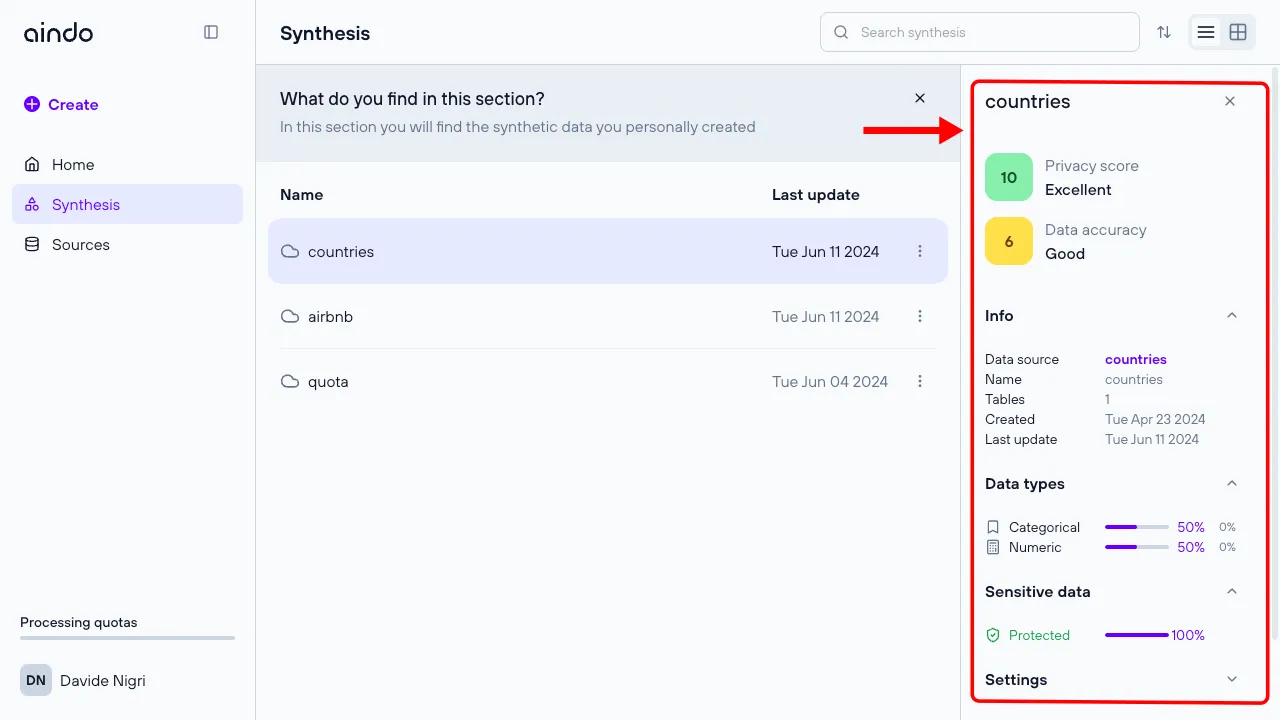
Quick details in list page
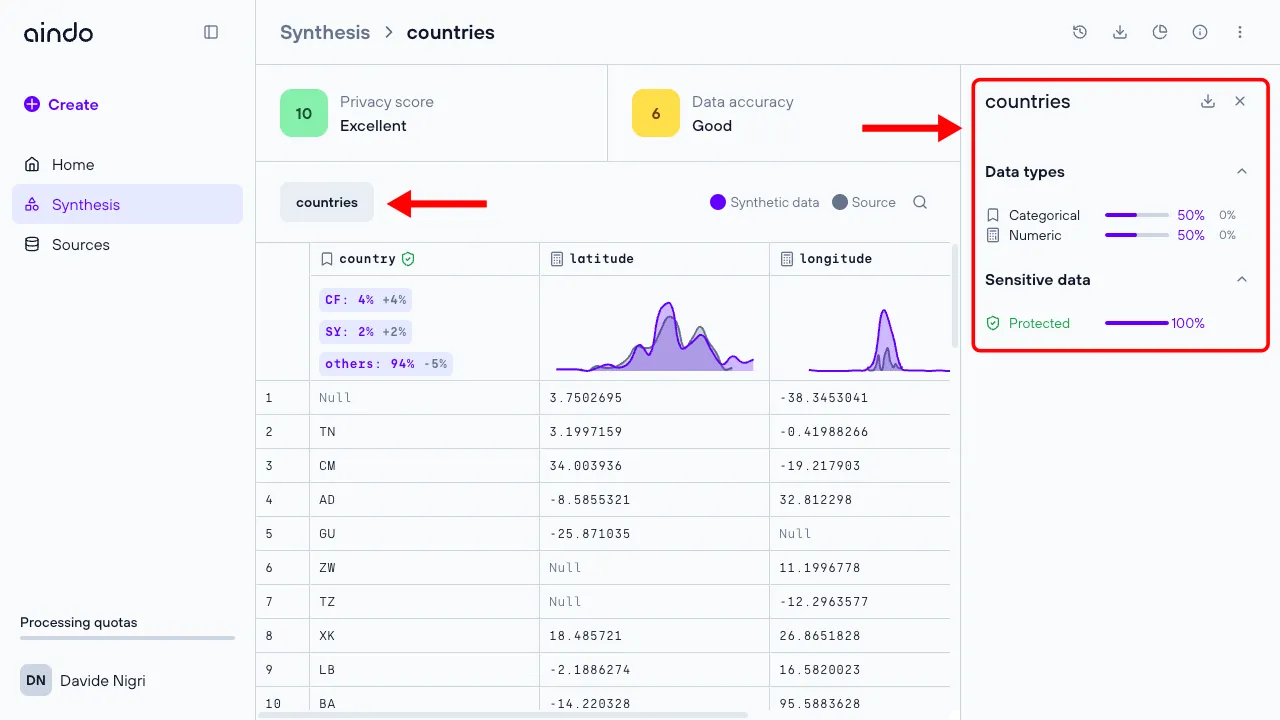
On the synthesis list page, click on a synthesis once to will open a side panel with general information about the synthesis, including scores, source information, data types, and model settings used in the synthesis.
View page
On the synthesis list page, double-click on a synthesis to open it.
The top of the synthesis view page, displays two important metrics that help assess the quality of the synthesis:
-
Privacy score: Indicates how well the generated synthetic data protects the privacy of real data subjects on a scale from 0 (all private information leaked) to 10 (no private information leaked). The privacy score is based on similarity metrics, a widely accepted approach to measuring privacy protection in synthetic and anonymized datasets.
-
Data accuracy: Indicates how well the synthetic data preserves the properties of the real data source on a scale from 0 (no information preserved) to 10 (all information relevant in analytics, software testing, research, AI development preserved). The data accuracy score is an aggregation of multiple widely accepted data fidelity and utility metrics.
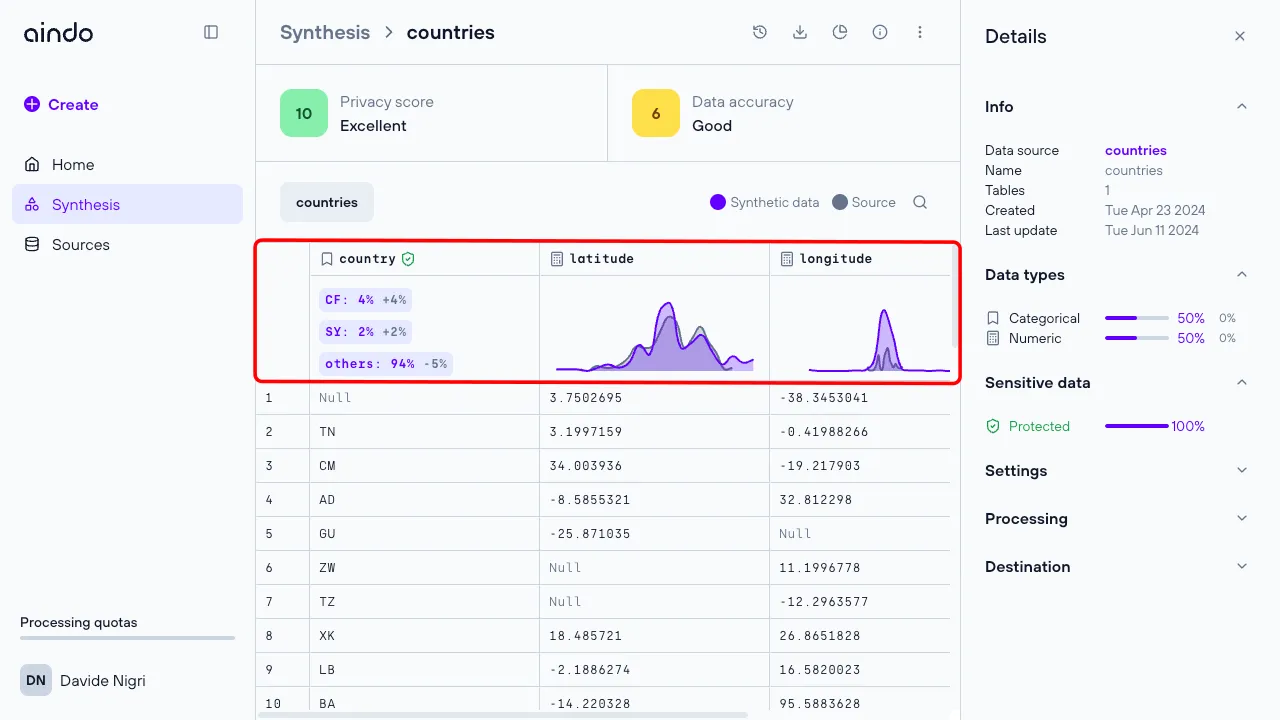
Below the metrics you can see the synthesized data. This section is similar to the source view page. Each column header has an icon indicating the column’s data type. If the original column contained sensitive data, the column header also has a ‘shield’ icon.
- A green shield icon indicates that the user chose not to synthesize the original sensitive data.
- A gray shield icon indicates that the user chose not to synthesize the original sensitive data
Under each column header, there is a small chart summarizing key statistics about that column.
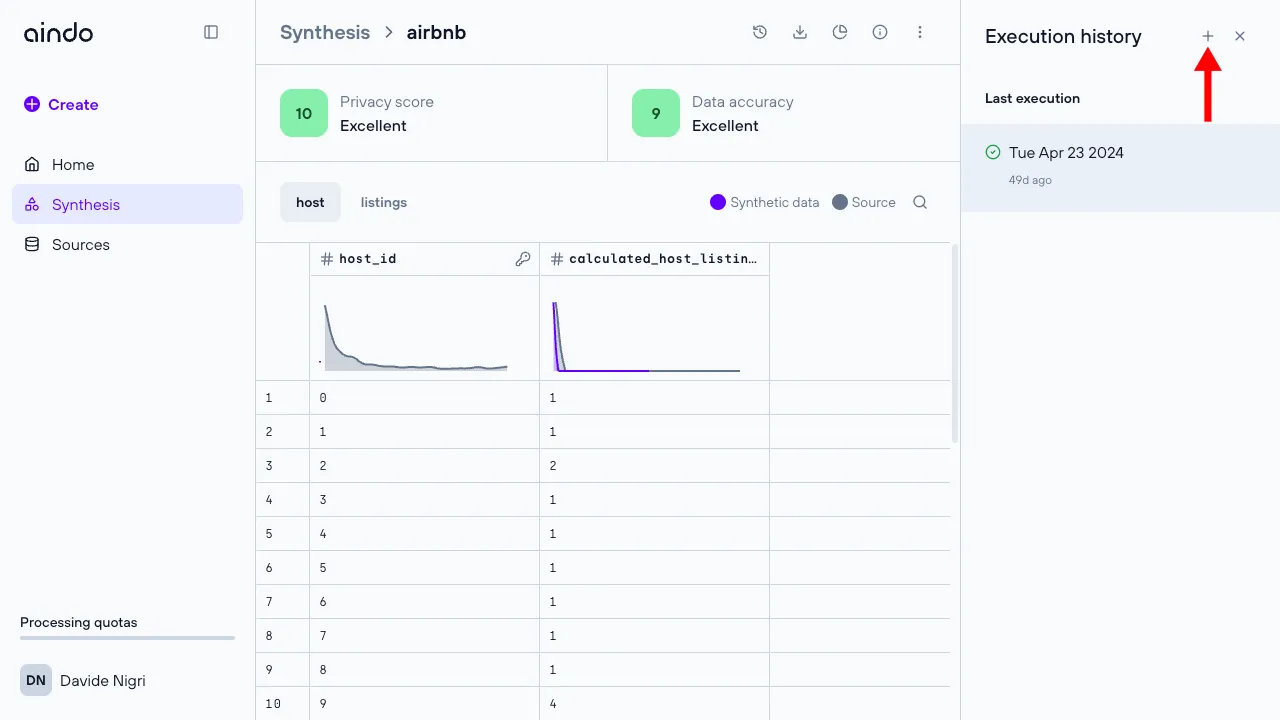
Executions
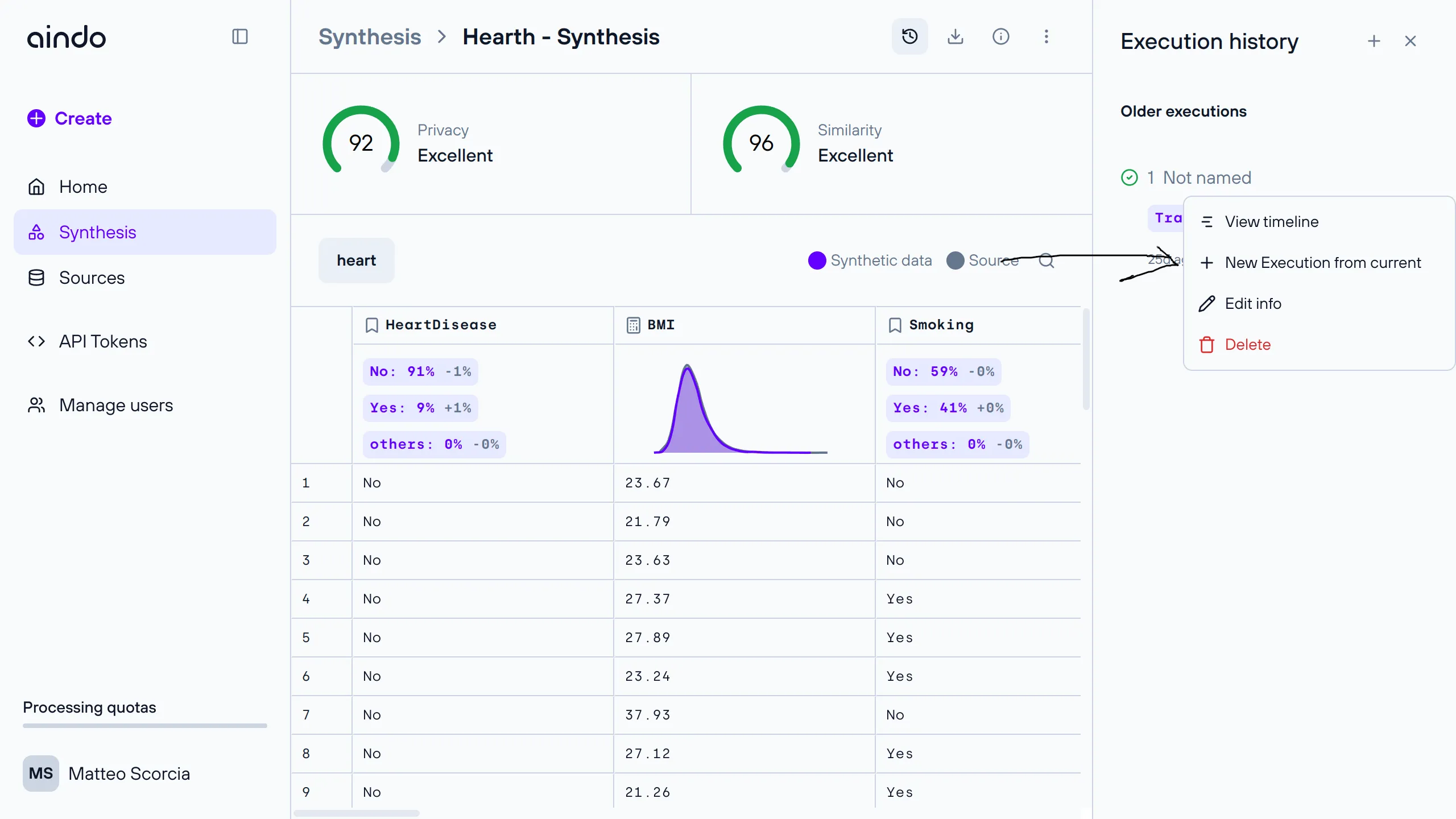
To view and manage multiple runs of the synthetic data generation, select the ‘History’ icon in the top right corner to access the execution history side panel, where you can create, rename, and delete executions of a specific synthesis.
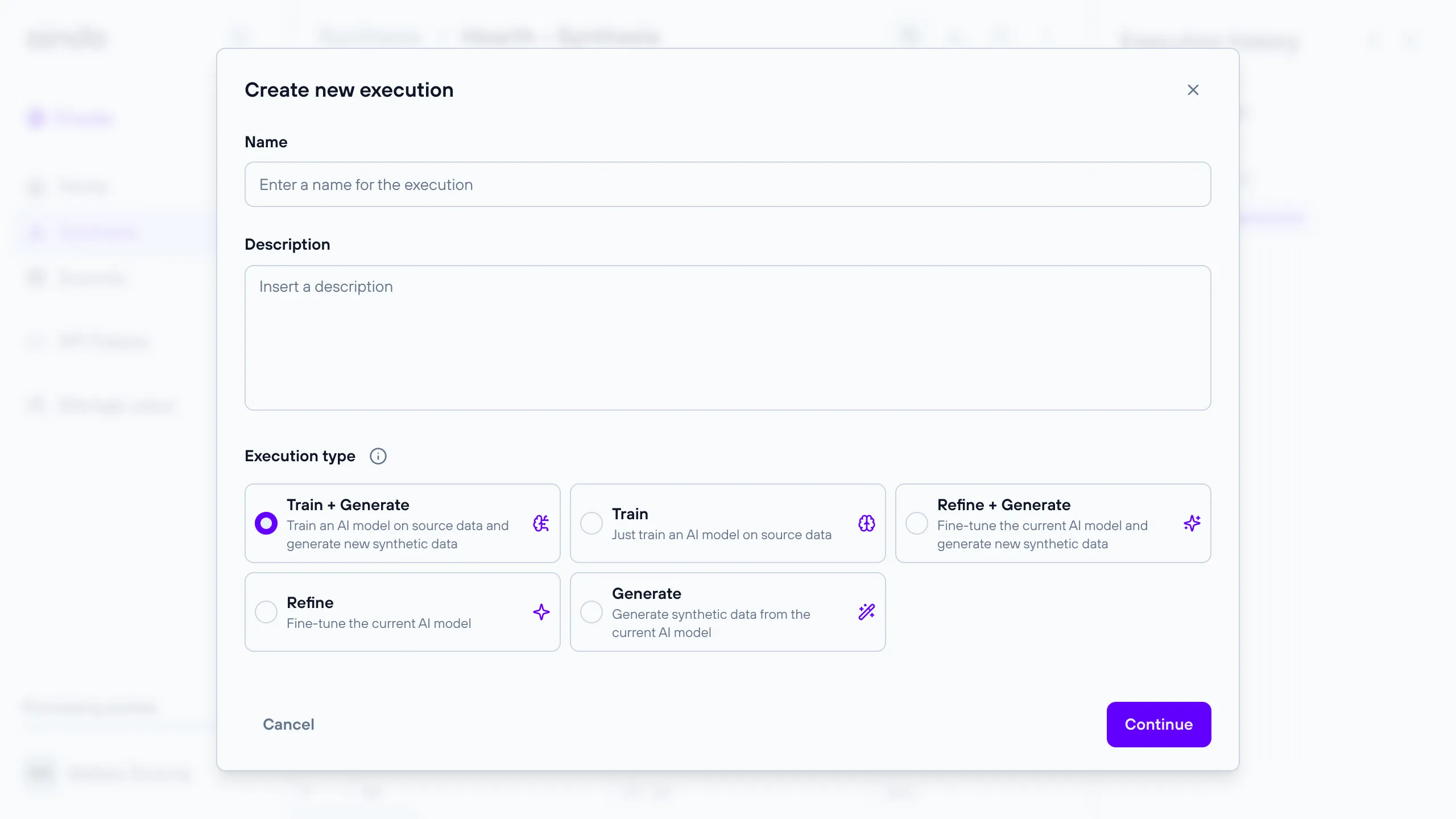
Types of execution
The Aindo platform supports five types of execution for generating synthetic data. Each type serves a specific purpose in the data synthesis workflow:
Each type of execution is designed to provide flexibility in managing the lifecycle of AI models and synthetic data generation. By understanding the specific purposes and steps involved in each execution type, you can better plan and execute the synthetic data generation processes to meet the specific needs.
Train + Generate
This execution type involves training an AI model on the source data and subsequently generating new synthetic data based on the trained model. It is the most comprehensive execution type, combining both model training and data generation in a single process.
Execution timeline steps:
- Data loading
- Preprocessing
- Building the Generative AI model
- Training the Generative AI model
- Synthesis (Output of the Generative AI model)
- Report generation
- Store the newly synthesized data
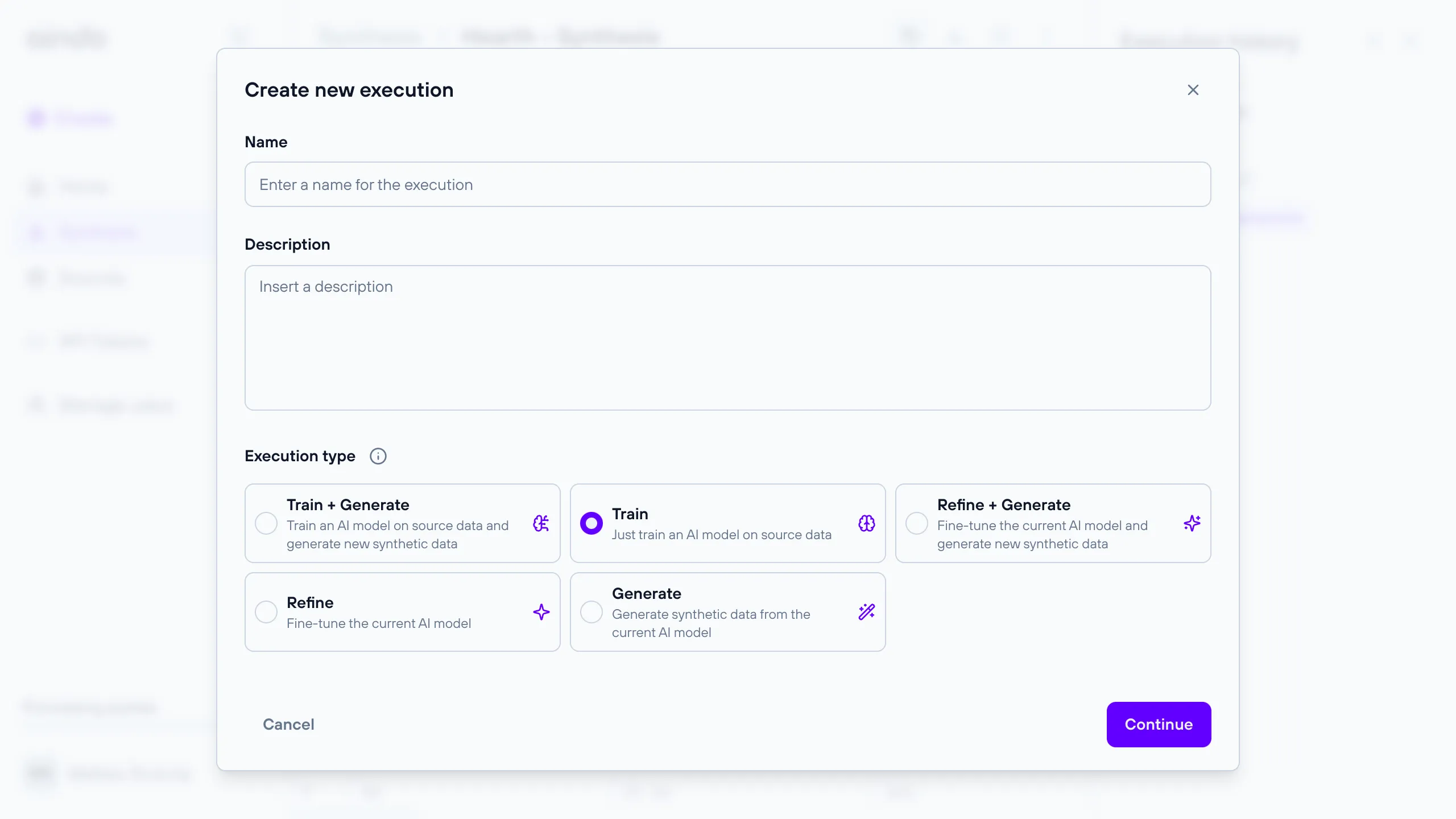
Train
This execution type focuses solely on training an AI model using the source data. It is useful when you need to update or create a model without generating synthetic data immediately.
Execution timeline steps:
- Data loading
- Preprocessing
- Building the Generative AI model
- Training the Generative AI model
- Report generation
Refine + Generate
This execution type allows you to fine-tune an existing AI model and then generate new synthetic data. It requires a reference to a previous execution that produced the initial model.
Execution timeline steps:
- Data loading
- Preprocessing
- Training the Generative AI model
- Synthesis (Output of the Generative AI model)
- Report generation
- Store the newly synthesized data
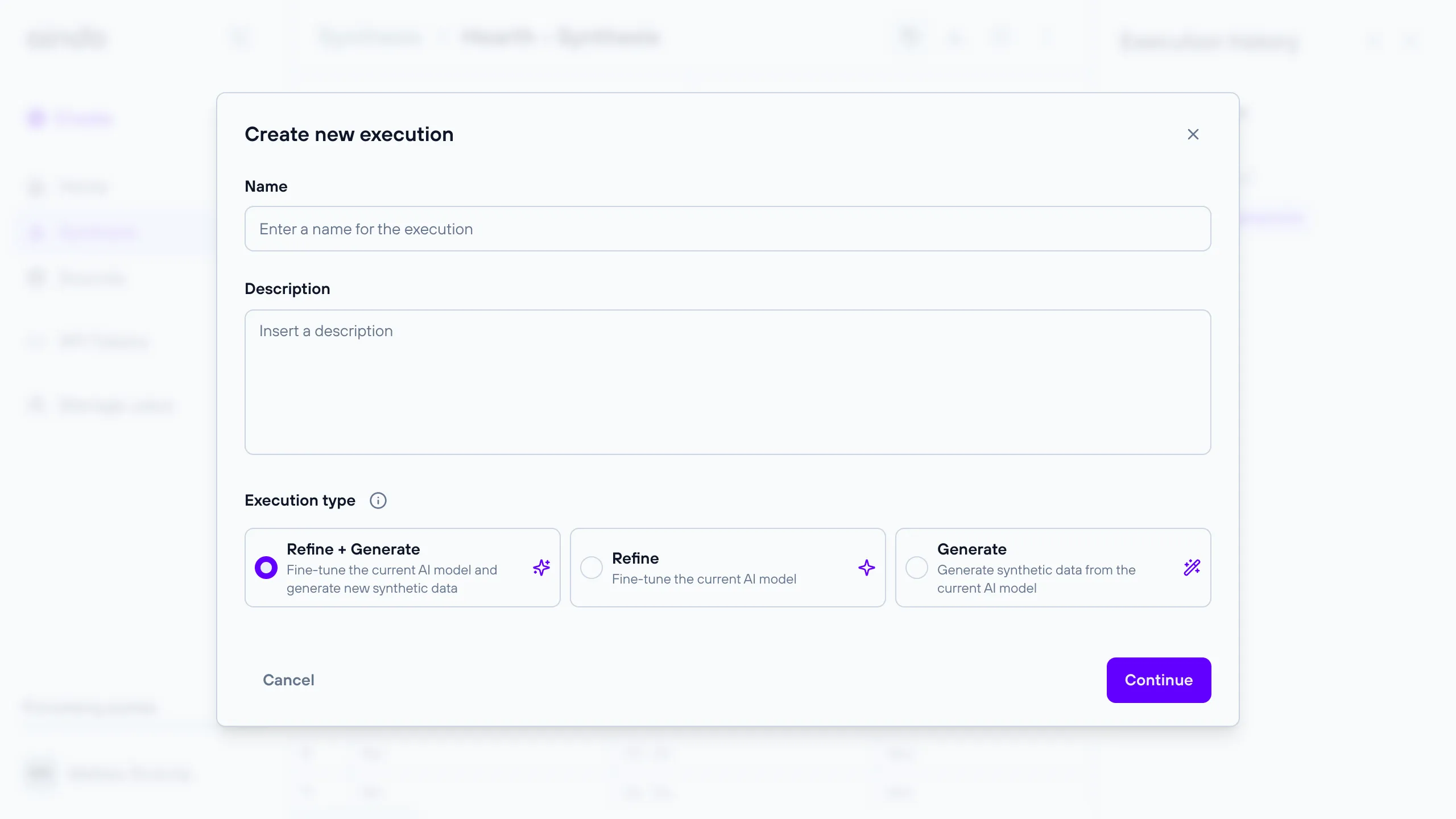
Refine
This execution type is used to fine-tune an existing AI model without generating synthetic data. It is useful for improving the model’s performance incrementally. It requires a reference to a previous execution that produced the initial model.
Execution timeline steps:
- Data loading
- Preprocessing
- Building the Generative AI model
- Training the Generative AI model
- Report generation
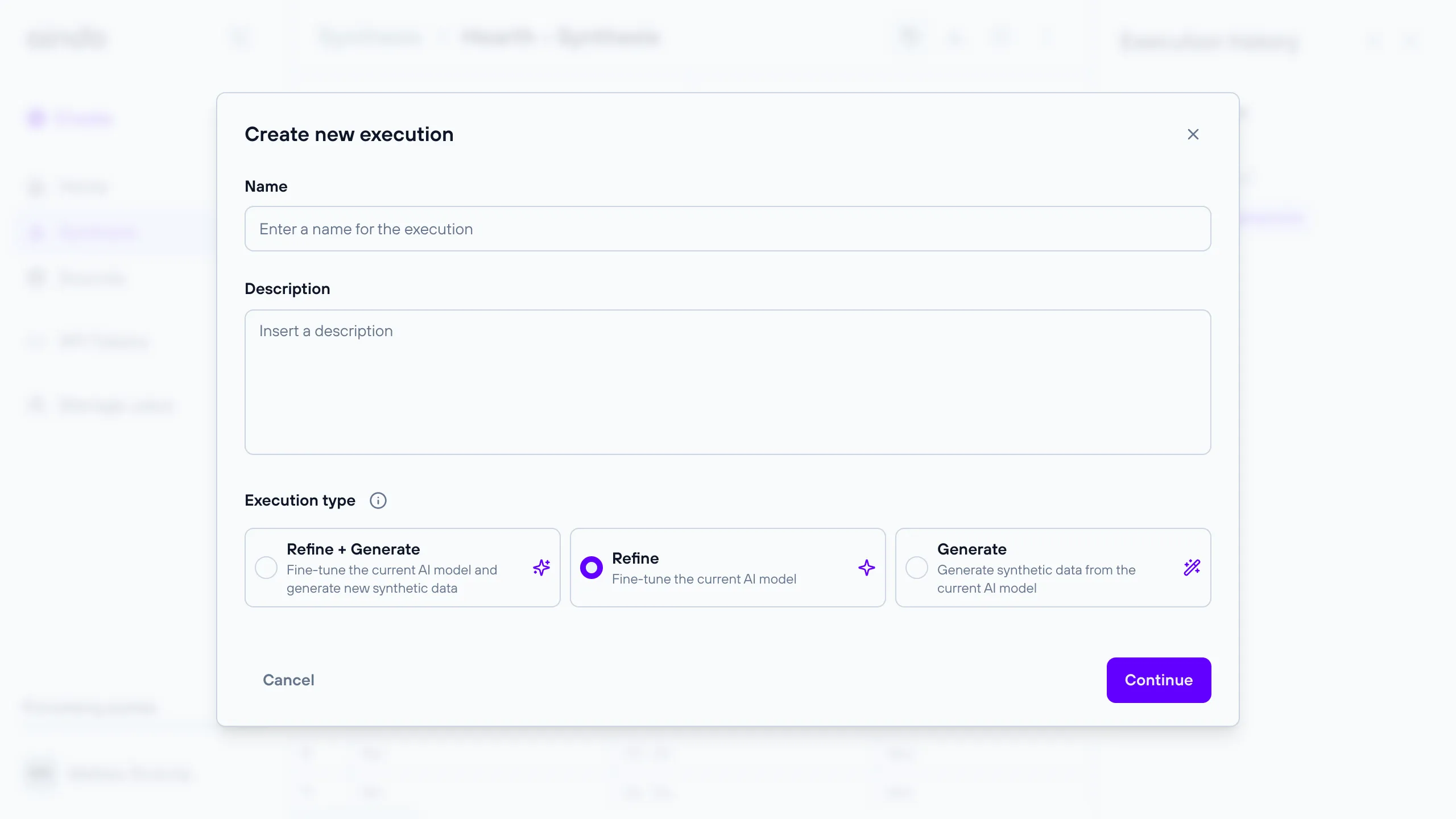
Generate
This execution type generates synthetic data using an already trained or refined AI model. It requires a reference to a previous execution that produced the model.
Execution timeline steps:
- Synthesis (Output of the Generative AI model)
- Report generation
- Store the newly synthesized data
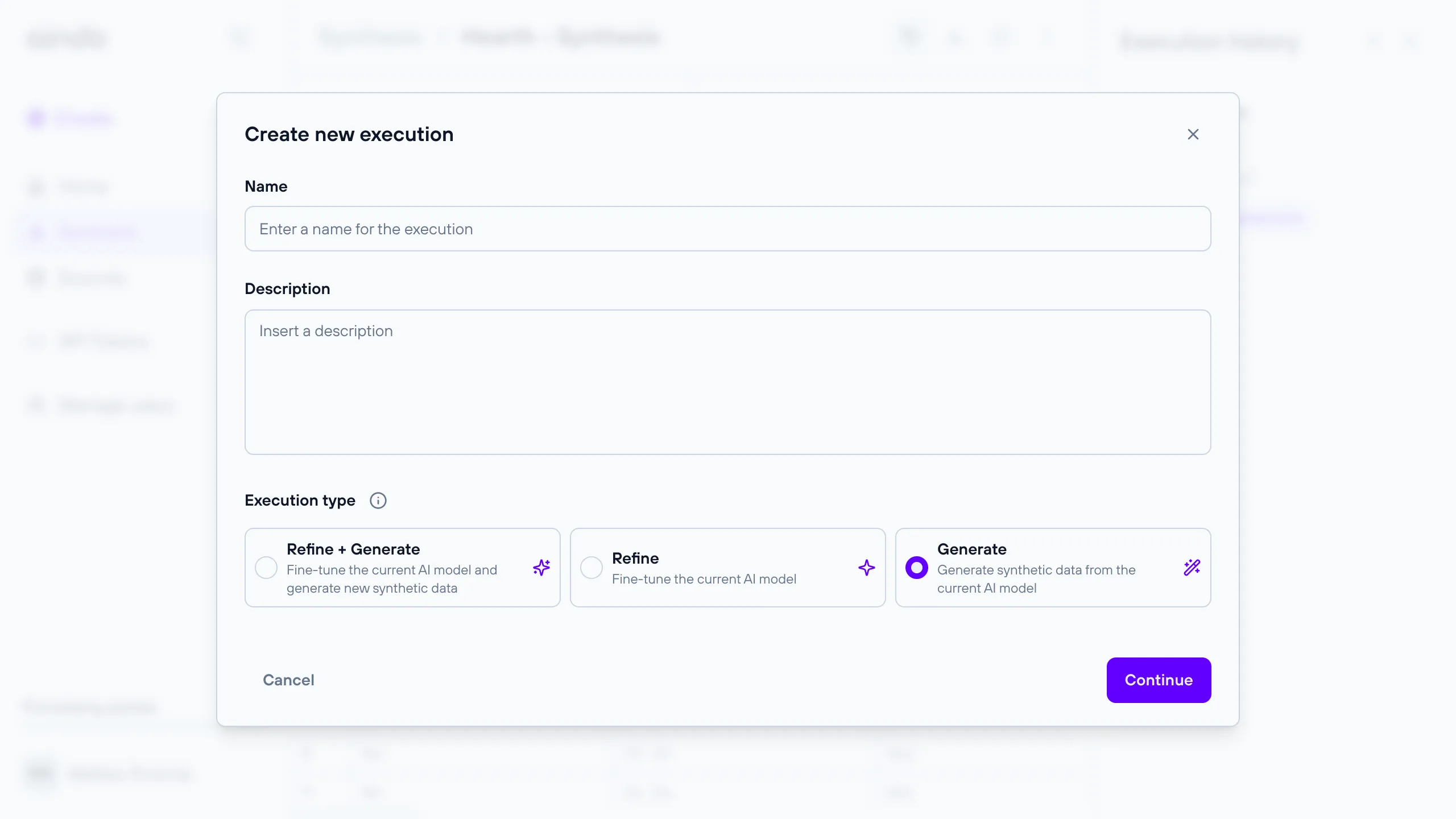
Execution timeline
The execution timeline dialog shows the various steps and statuses related to generating synthetic data for the current execution.
The steps involved in generating a synthesis are:
- Data loading
- Preprocessing
- Building the Generative AI model
- Training the Generative AI model
- Synthesis (Output of the Generative AI model)
- Report generation
- Store the newly synthesized data
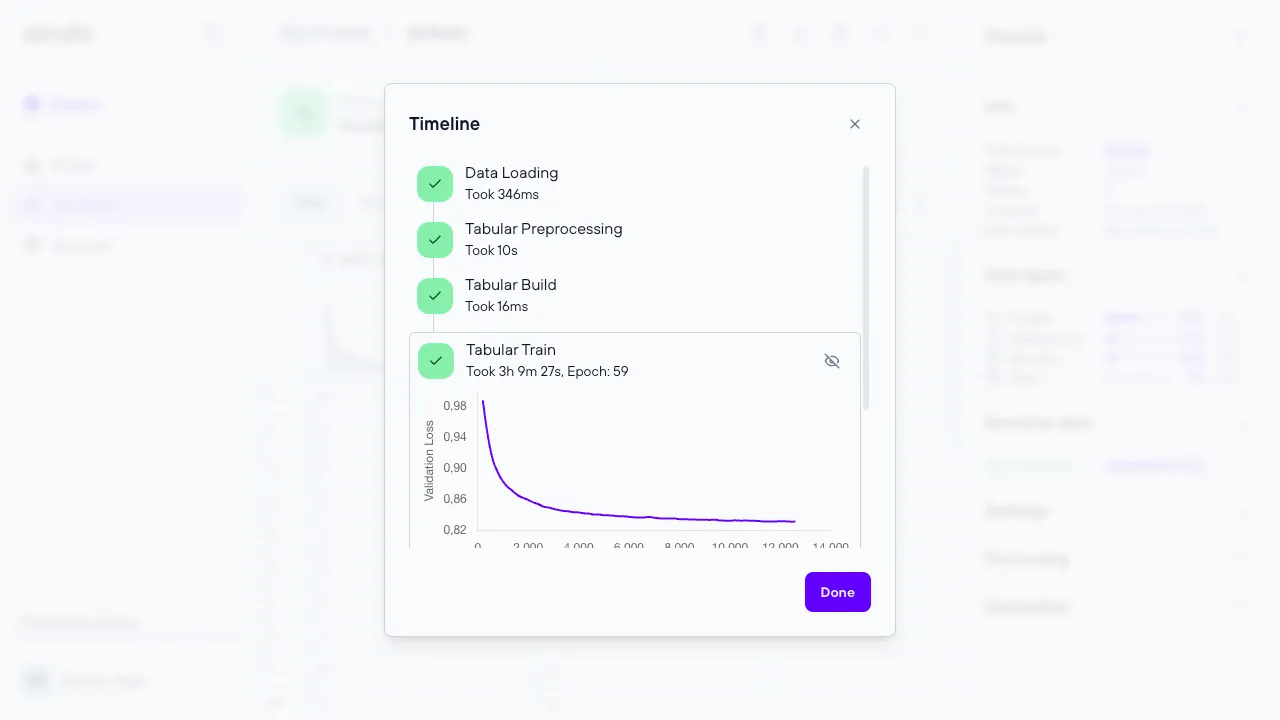 The execution timeline steps differ depending on the type of execution.
The execution timeline steps differ depending on the type of execution.
Report
The report is a PDF containing numerous statistics, needed to thoroughly assess the quality of the synthetic data compared to the original data. The report helps evaluate the synthetic data in detail.
To download the report, select the “Download” icon in the top right corner of the page and then select “Report.”
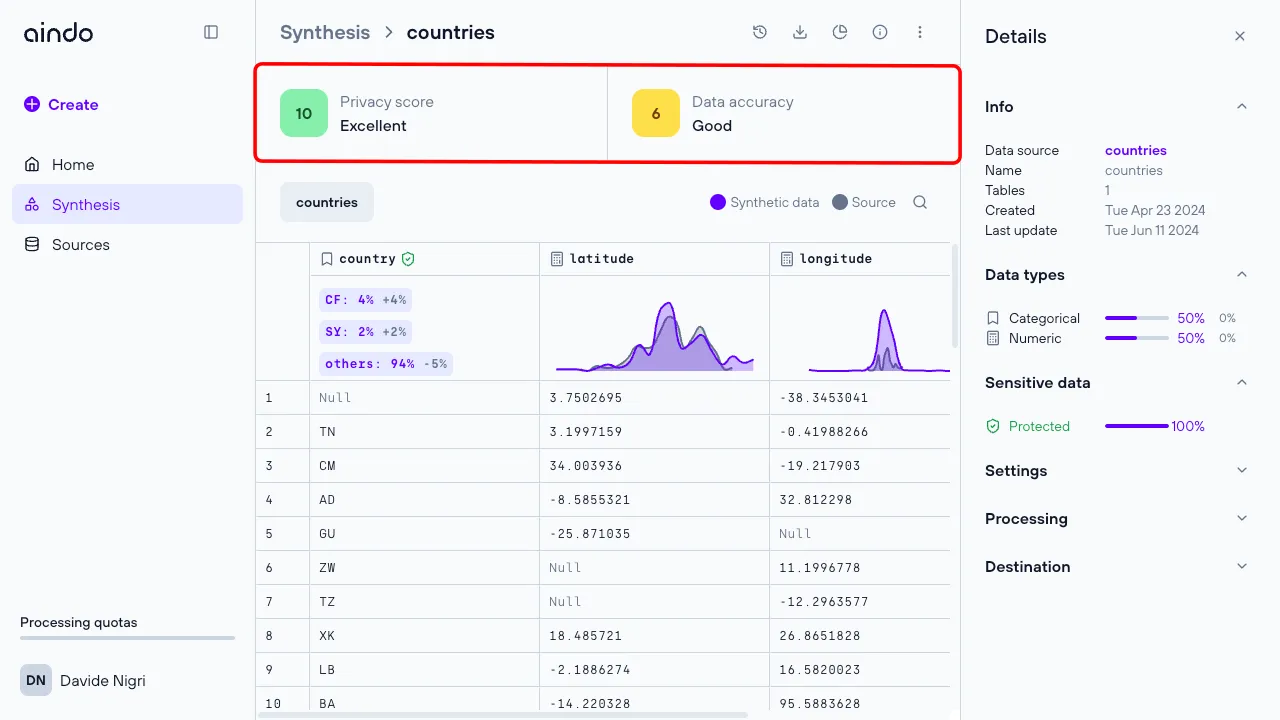
Quick details synthesis
Click the “Info” icon in the top right corner to open a side panel with general information about the synthetic dataset, data types, and synthesis settings.
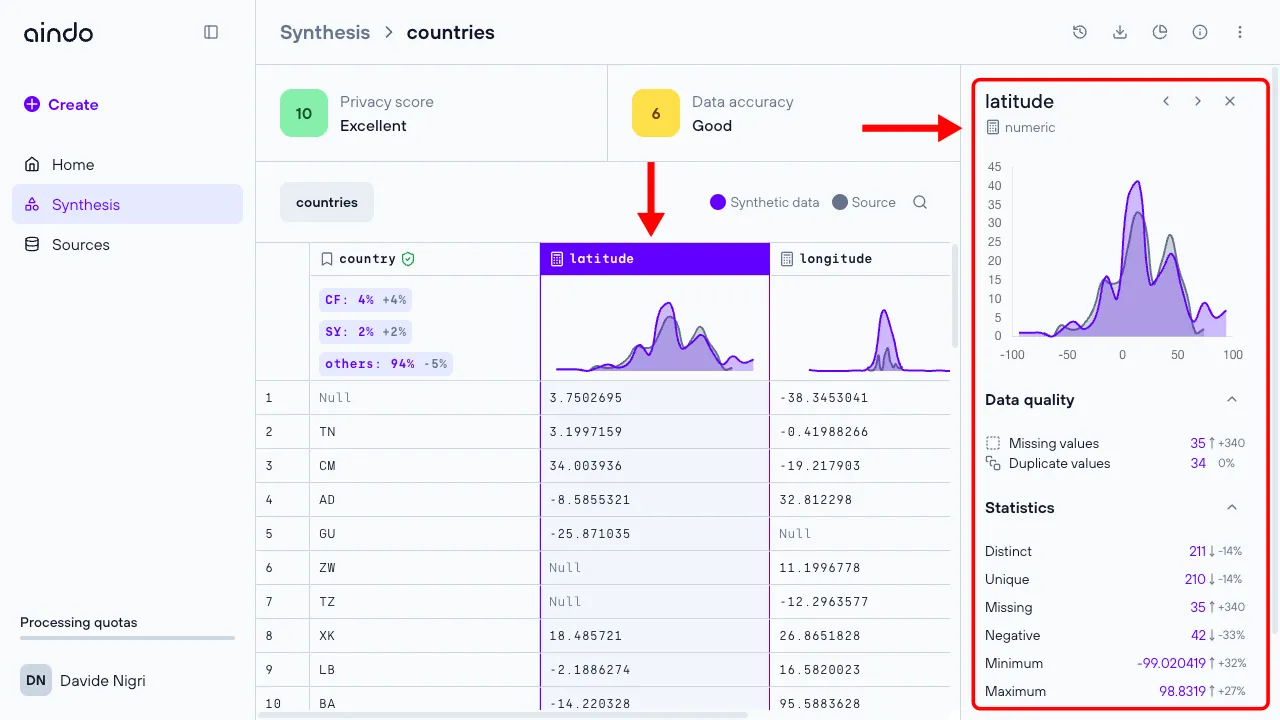
Quick details column
Click directly on a column to open a side panel with more detailed information about the selected column.
Quick details table
Click on the name of a table to open a side panel with more detailed information about the selected table.